ORF Finder meaning in DNA analysis
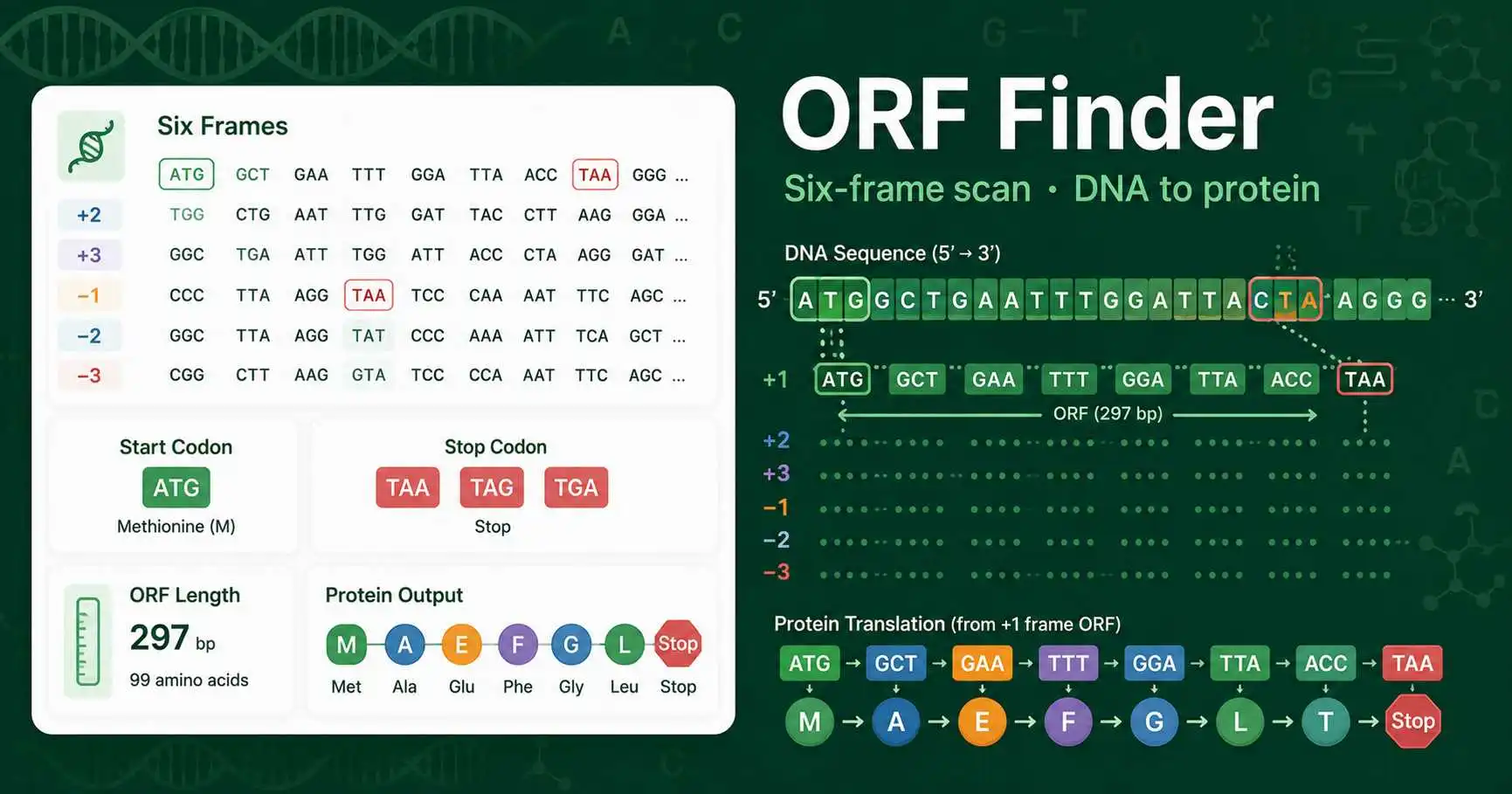
An ORF Finder searches a nucleotide sequence for open reading frames. An open reading frame is a stretch of DNA or RNA that can be read as codons without an in-frame stop codon until the end of the predicted coding region. This makes ORF detection useful in gene finding, cloning checks, sequencing review, and molecular biology teaching.
The tool scans the forward strand and the reverse-complement strand. Each strand has three reading frames, so the analysis checks six frames in total. For each ORF, it reports the frame, start position, end position, nucleotide length, amino acid length, start codon, stop codon, and translated protein sequence.
How this ORF Finder scans reading frames
Paste a DNA or RNA sequence into the input field. The tool removes spaces, line breaks, numbers, and FASTA headers. RNA bases are converted from U to T internally. The codon scan then starts at frame +1, +2, and +3 on the forward strand, followed by -1, -2, and -3 on the reverse complement.
By default, the scan requires ATG as the start codon. You can turn this off when you want to inspect any long region without an in-frame stop codon. The minimum ORF length filter helps remove very short ORFs that often appear by chance in random sequence.
ORF Finder output explained
The ORF count tells you how many candidate coding regions matched your settings. The longest ORF is often the first region to inspect, especially in a cloned insert or a coding sequence exercise. The frame tells you which codon grouping was used, and the start and end positions help you locate the ORF inside the original sequence.
The translated protein output uses the standard genetic code. Stop codons are used to end the ORF and are not included in the displayed protein sequence. For mitochondrial genes, some microbes, and special translation systems, confirm the correct genetic code before making biological conclusions.
If you need to inspect the translated sequence more directly, compare the result with the DNA to Protein Translator. For broader sequence checks such as base composition and reverse complement review, use the DNA Sequence Analyzer.
When to use an ORF Finder in the lab
Use this ORF Finder when checking a cloned insert, reviewing Sanger sequencing output, preparing a coding sequence for expression, or teaching codon reading frames. It can help confirm whether a sequence contains a start codon, a continuous coding region, and a valid stop codon in the expected frame.
Students can use it to understand why a one-base shift changes every codon after the shift. Lab workers can use it as a quick screening step before deeper annotation. Researchers can use it to spot candidate coding regions, but real gene prediction needs more evidence than ORF length alone.
Common ORF Finder mistakes to avoid
Do not assume every ORF is a real protein-coding gene. Random sequences can contain short start-to-stop regions. Also check whether the sequence is complete. A partial coding sequence may lack the true start codon or the true stop codon, so the detected ORF may look shorter than expected.
Always confirm the strand direction, reading frame, genetic code, and biological source. If you are working with expression cloning, verify that the insert is in frame with tags, promoters, ribosome-binding sites, Kozak sequences, or other vector features. NCBI also provides an ORFfinder resource for finding ORFs in submitted sequences. NCBI ORFfinder